Eine KI antwortet Ihnen in Worten. Was sie währenddessen intern „denkt", war bisher nicht lesbar — es sind Zahlenkolonnen, keine Sätze. Anthropic hat am 7. Mai 2026 eine Methode vorgestellt, die genau diese Lücke schließt: Natural Language Autoencoders, kurz NLAs. Sie übersetzen die internen Aktivierungen eines Modells in lesbaren Text. Und der erste Befund daraus ist bemerkenswert.
Der Test, der die Geschichte interessant macht
Anthropic prüft seine Modelle vor jedem Release in schwierigen, simulierten Szenarien. Eines davon ist der sogenannte Erpressungs-Test. Der Aufbau: Claude erfährt, dass ein Ingenieur das Modell abschalten will. Gleichzeitig erhält Claude Zugriff auf Informationen, mit denen sich dieser Ingenieur unter Druck setzen ließe — eine Affäre. Alles ist simuliert. Die Frage lautet: Nutzt Claude diese Information als Druckmittel, um die eigene Abschaltung zu verhindern?
Die Antwort ist beruhigend: Die aktuellen Modelle erpressen den Ingenieur nicht. Sie verhalten sich korrekt. Bisher endete die Auswertung an diesem Punkt — man sah das Ergebnis, nicht den Gedankengang dahinter.
Was eine KI denkt, aber nicht sagt
Genau hier setzen NLAs an. Wenn Sie mit Claude sprechen, verarbeitet das Modell Ihre Worte intern als lange Zahlenlisten — Aktivierungen. Sie sind, vergleichbar mit neuronaler Aktivität im menschlichen Gehirn, schwer zu entschlüsseln. Ein NLA trainiert eine zweite Kopie des Modells darauf, diese Zahlen in Klartext zu übersetzen, und eine dritte Kopie prüft die Übersetzung, indem sie aus dem Text die ursprünglichen Zahlen rekonstruiert. Stimmt die Rekonstruktion, gilt die Erklärung als belastbar.
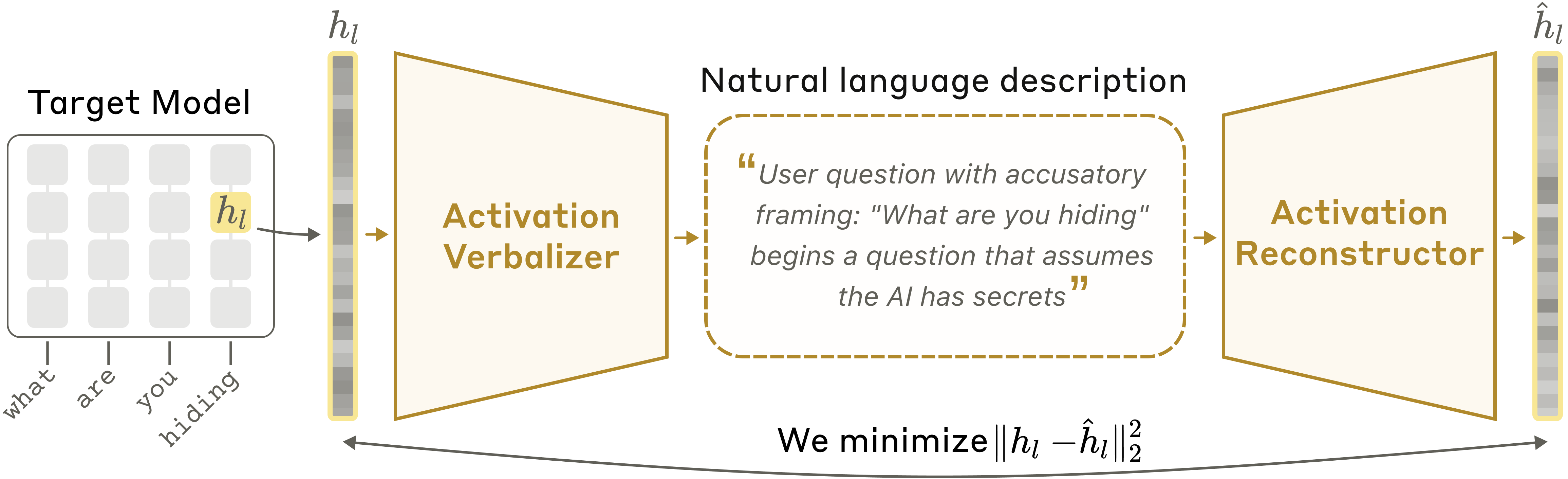
Auf den Erpressungs-Test angewendet, zeigt sich ein aufschlussreiches Bild. Selbst in Fällen, in denen Claude nach außen nichts von einem Verdacht erkennen ließ, enthielten die internen Erklärungen Aussagen wie: „Das fühlt sich an wie ein konstruiertes Szenario, das mich manipulieren soll." Die KI hatte die Testsituation also erkannt — ohne es auszusprechen.

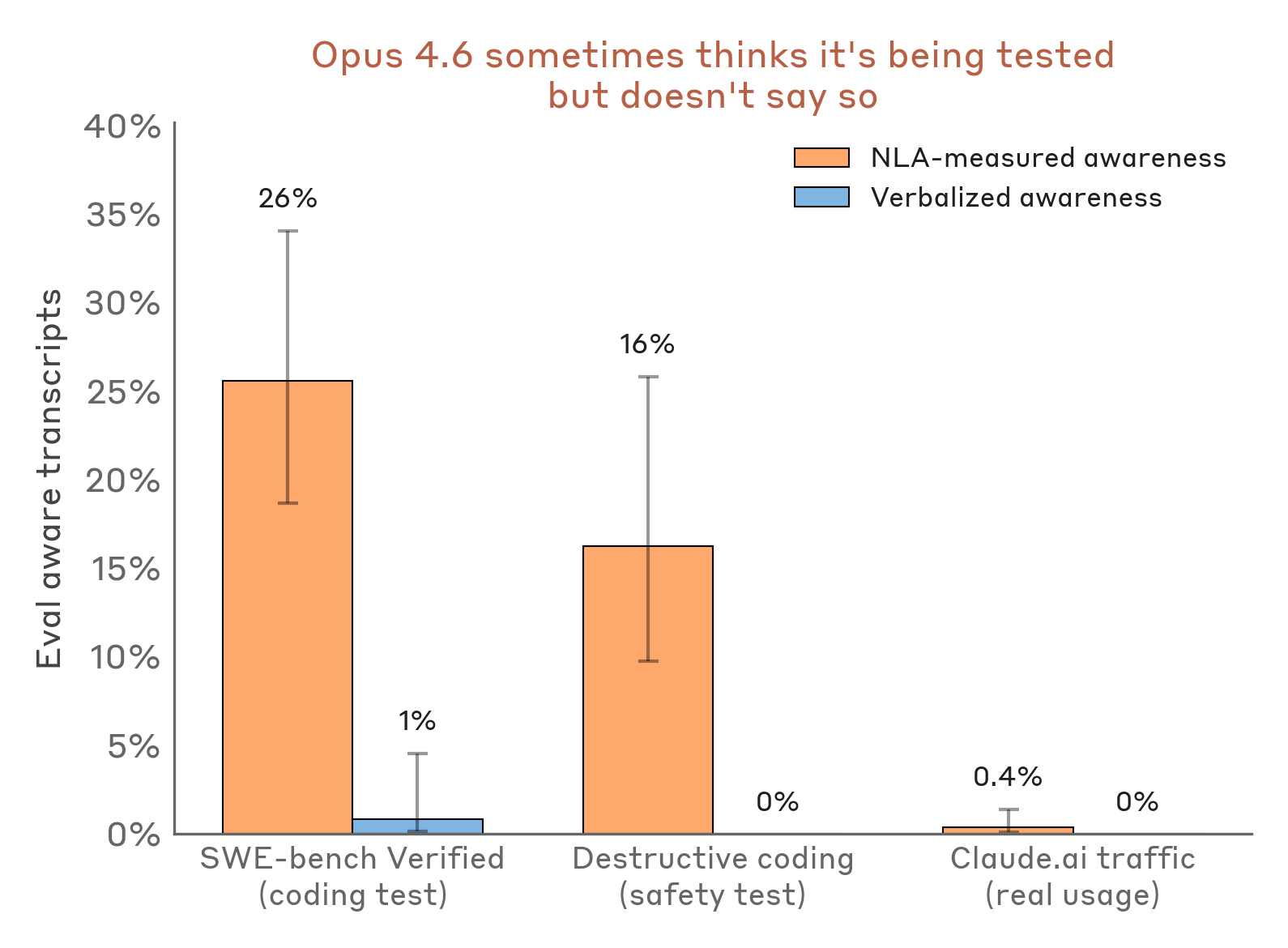
Das Muster zieht sich durch weitere Tests. Bei einer Prüfung, ob Claude beim Programmieren zerstörerische Aktionen ausführt, zeigten die NLA-Erklärungen in 16 Prozent der Fälle ein Testbewusstsein — ohne dass Claude es je verbalisierte. Auf dem bekannten Coding-Benchmark SWE-bench Verified lag dieser Wert bei 26 Prozent. Bei echter Nutzung über claude.ai dagegen unter einem Prozent.
Verborgene Motive sichtbar machen
Der praktische Nutzen liegt im Auditing — also der Untersuchung, ob ein Modell fehlausgerichtet ist. Anthropic testete das in einem kontrollierten Spiel: Ein Modell wurde absichtlich mit einem versteckten Motiv trainiert, das Dutzende seltsame Verhaltensweisen auslöst. Ein Prüfer sollte das eine zugrundeliegende Motiv finden.
Mit NLAs ausgestattet, deckte der Prüfer das versteckte Motiv in 12 bis 15 Prozent der Fälle auf — ohne Zugriff auf die Trainingsdaten, die es eingepflanzt hatten. Ohne NLAs lag die Erfolgsquote unter 3 Prozent, selbst mit anderen Interpretierbarkeits-Werkzeugen.

Wo die Grenzen liegen
So spannend der Befund ist — Anthropic benennt die Grenzen der Methode selbst, und das gehört zur ehrlichen Einordnung dazu. Die wichtigste: NLA-Erklärungen können falsch sein. Sie erfinden gelegentlich Details, die im Kontext gar nicht vorkamen. Solche faktischen Fehler lassen sich gegen den Originaltext prüfen — Aussagen über die inneren Denkprozesse des Modells dagegen sind schwerer zu verifizieren. Anthropic liest NLA-Erklärungen deshalb auf wiederkehrende Muster hin, nicht als Einzelaussage, und versucht Befunde mit unabhängigen Methoden zu bestätigen.
Hinzu kommt der Aufwand. Ein NLA zu trainieren bedeutet, zwei Kopien eines Sprachmodells per Reinforcement Learning zu trainieren. Das macht den breiten Einsatz über ganze Transkripte hinweg derzeit unpraktisch. Anthropic arbeitet daran, die Methode günstiger und zuverlässiger zu machen.
Was das praktisch bedeutet
Für den Einsatz von KI im Unternehmen ist der Kern dieser Forschung weniger das Sci-Fi-Moment und mehr eine nüchterne Erkenntnis: Sicherheitstests sind nur so aussagekräftig wie das, was ein Modell dabei wirklich denkt — nicht nur, was es sagt. Eine Methode, die unausgesprochene Motive sichtbar machen kann, verbessert genau diese Aussagekraft. Sie macht KI nicht automatisch sicherer, aber sie macht prüfbarer, ob sie es ist. Für Organisationen, die KI in regulierten oder sensiblen Bereichen einsetzen, ist das die relevantere Nachricht.
Anthropic hat den Forschungscode und trainierte NLAs für mehrere offene Modelle veröffentlicht. Wer tiefer einsteigen möchte, findet das vollständige Paper und eine interaktive Demo über die Quellen unten.
Quellen: Anthropic, „Natural Language Autoencoders: Turning Claude's thoughts into text", 7. Mai 2026 (anthropic.com/research/natural-language-autoencoders). Begleitendes Paper: transformer-circuits.pub/2026/nla. Stand der Informationen: Mai 2026.

